#Scraping Wayfair Products with Python and Beautiful Soup
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Quote
Introduction In this blog, we will show you how we Extract Wayfair product utilizing BeautifulSoup and Python in an elegant and simple manner. This blog targets your needs to start on a practical problem resolving while possession it very modest, so you need to get practical and familiar outcomes fast as likely. So the main thing you need to check that we have installed Python 3. If don’t, you need to install Python 3 before you get started. pip3 install beautifulsoup4 We also require the library's lxml, soupsieve, and requests to collect information, fail to XML, and utilize CSS selectors. Mount them utilizing. pip3 install requests soupsieve lxml When installed, you need to open the type in and editor. # -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests Now go to Wayfair page inspect and listing page the details we can need. It will look like this. wayfair-screenshot Let’s get back to the code. Let's attempt and need data by imagining we are a browser like this. # -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url = 'https://www.wayfair.com/rugs/sb0/area-rugs-c215386.html' response=requests.get(url,headers=headers) soup=BeautifulSoup(response.content,'lxml') Save scraper as scrapeWayfais.py If you route it python3 scrapeWayfair.py The entire HTML page will display. Now, let's utilize CSS selectors to acquire the data you need. To peruse that, you need to get back to Chrome and review the tool. wayfair-code We observe all the separate product details are checked with the period ProductCard-container. We scrape this through the CSS selector '.ProductCard-container' effortlessly. So here you can see how the code will appear like. # -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url = 'https://www.wayfair.com/rugs/sb0/area-rugs-c215386.html' response=requests.get(url,headers=headers) soup=BeautifulSoup(response.content,'lxml') for item in soup.select('.ProductCard-container'): try: print('----------------------------------------') print(item) except Exception as e: #raise e print('') This will print out all the substance in all the fundamentals that contain the product information. code-1 We can prefer out periods inside these file that comprise the information we require. We observe that the heading is inside a # -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url = 'https://www.wayfair.com/rugs/sb0/area-rugs-c215386.html' response=requests.get(url,headers=headers) soup=BeautifulSoup(response.content,'lxml') for item in soup.select('.ProductCard-container'): try: print('----------------------------------------') #print(item) print(item.select('.ProductCard-name')[0].get_text().strip()) print(item.select('.ProductCard-price--listPrice')[0].get_text().strip()) print(item.select('.ProductCard-price')[0].get_text().strip()) print(item.select('.pl-ReviewStars-reviews')[0].get_text().strip()) print(item.select('.pl-VisuallyHidden')[2].get_text().strip()) print(item.select('.pl-FluidImage-image')[0]['src']) except Exception as e: #raise e print('') If you route it, it will publish all the information. code-2 Yeah!! We got everything. If you need to utilize this in creation and need to scale millions of links, after that you need to find out that you will need IP blocked effortlessly by Wayfair. In such case, utilizing a revolving service proxy to replace IPs is required. You can utilize advantages like API Proxies to mount your calls via pool of thousands of inhabited proxies. If you need to measure the scraping speed and don’t need to fix up infrastructure, you will be able to utilize our Cloud-base scraper RetailGators.com to effortlessly crawl millions of URLs quickly from our system. If you are looking for the best Scraping Wayfair Products with Python and Beautiful Soup, then you can contact RetailGators for all your queries.
source code: https://www.retailgators.com/scraping-wayfair-products-with-python-and-beautiful-soup.php
#Scraping Wayfair Products with Python and Beautiful Soup#Scraping Wayfair Products with Python#Extract Wayfair product utilizing BeautifulSoup and Python
0 notes
Link

Here, we will see how to scrape Wayfair products with Python & BeautifulSoup easily and stylishly.
This blog helps you get started on real problem solving whereas keeping that very easy so that you become familiar as well as get real results as quickly as possible.
The initial thing we want is to ensure that we have installed Python 3 and if not just install it before proceeding any further.
After that, you may install BeautifulSoup using
install BeautifulSoup
pip3 install beautifulsoup4
We would also require LXML, library’s requests, as well as soupsieve for fetching data, break that down to the XML, as well as utilize CSS selectors. Then install them with:
pip3 install requests soupsieve lxml
When you install it, open the editor as well as type in.
s# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests
Now go to the listing page of Wayfair products to inspect data we could get.
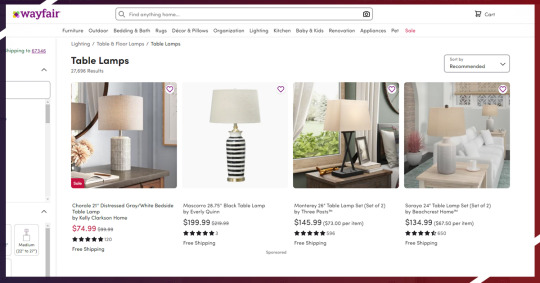
That is how it will look:
Now, coming back to our code, let���s get the data through pretending that we are the browser like that.
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url = 'https://www.wayfair.com/rugs/sb0/area-rugs-c215386.html' response=requests.get(url,headers=headers) soup=BeautifulSoup(response.content,'lxml')
Then save it as a scrapeWayfair.py.
In case, you run that.
python3 scrapeWayfair.py
You will get the entire HTML page.
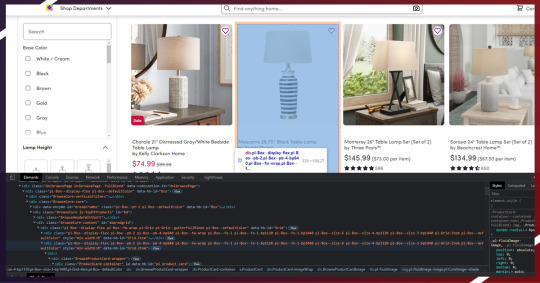
Now, it’s time to utilize CSS selectors for getting the required data. To do it, let’s use Chrome as well as open an inspect tool.
We observe that all individual products data are controlled within a class ‘ProductCard-container.’ We could scrape this using CSS selector ‘.ProductCard-container’ very easily. Therefore, let’s see how the code will look like:
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url = 'https://www.wayfair.com/rugs/sb0/area-rugs-c215386.html' response=requests.get(url,headers=headers) soup=BeautifulSoup(response.content,'lxml') for item in soup.select('.ProductCard-container'): try: print('----------------------------------------') print(item) except Exception as e: #raise e print('')
It will print the content of all the elements, which hold the product’s data.

Now, we can choose classes within these rows, which have the required data. We observe that a title is within the
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url = 'https://www.wayfair.com/rugs/sb0/area-rugs-c215386.html' response=requests.get(url,headers=headers) soup=BeautifulSoup(response.content,'lxml') for item in soup.select('.ProductCard-container'): try: print('----------------------------------------') #print(item) print(item.select('.ProductCard-name')[0].get_text().strip()) print(item.select('.ProductCard-price--listPrice')[0].get_text().strip()) print(item.select('.ProductCard-price')[0].get_text().strip()) print(item.select('.pl-ReviewStars-reviews')[0].get_text().strip()) print(item.select('.pl-VisuallyHidden')[2].get_text().strip()) print(item.select('.pl-FluidImage-image')[0]['src']) except Exception as e: #raise e print('')
In case, you run that, it would print all the information.
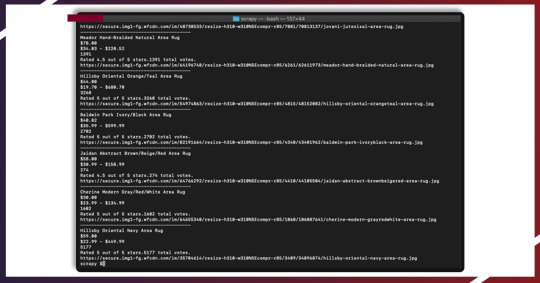
And that’s it!! We have done that!
If you wish to utilize this in the production as well as wish to scale it to thousand links, you will discover that you would get the IP blocked very easily with Wayfair. With this scenario, utilizing rotating proxy services for rotating IPs is nearly a must. You may utilize the services including Proxies API for routing your calls using the pool of millions of domestic proxies.
In case, you wish to scale crawling speed as well as don’t wish to set the infrastructure, then you can utilize our Wayfair data crawler to easily scrape thousands of URLs with higher speed from the network of different crawlers. For more information, contact us!
0 notes
Text
Scraping Wayfair Products with Python and Beautiful Soup
0 notes
Link
Introduction
In this blog, we will show you how we Extract Wayfair product utilizing BeautifulSoup and Python in an elegant and simple manner.
This blog targets your needs to start on a practical problem resolving while possession it very modest, so you need to get practical and familiar outcomes fast as likely.
So the main thing you need to check that we have installed Python 3. If don’t, you need to install Python 3 before you get started.
pip3 install beautifulsoup4
We also require the library's lxml, soupsieve, and requests to collect information, fail to XML, and utilize CSS selectors. Mount them utilizing.
pip3 install requests soupsieve lxml
When installed, you need to open the type in and editor.
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests
Now go to Wayfair page inspect and listing page the details we can need.
It will look like this.
Let’s get back to the code. Let's attempt and need data by imagining we are a browser like this.
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url = 'https://www.wayfair.com/rugs/sb0/area-rugs-c215386.html' response=requests.get(url,headers=headers) soup=BeautifulSoup(response.content,'lxml')
Save scraper as scrapeWayfais.py
If you route it
python3 scrapeWayfair.py
The entire HTML page will display.
Now, let's utilize CSS selectors to acquire the data you need. To peruse that, you need to get back to Chrome and review the tool.
We observe all the separate product details are checked with the period ProductCard-container. We scrape this through the CSS selector '.ProductCard-container' effortlessly. So here you can see how the code will appear like.
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url = 'https://www.wayfair.com/rugs/sb0/area-rugs-c215386.html' response=requests.get(url,headers=headers) soup=BeautifulSoup(response.content,'lxml') for item in soup.select('.ProductCard-container'): try: print('----------------------------------------') print(item) except Exception as e: #raise e print('')
This will print out all the substance in all the fundamentals that contain the product information.
We can prefer out periods inside these file that comprise the information we require. We observe that the heading is inside a
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url = 'https://www.wayfair.com/rugs/sb0/area-rugs-c215386.html' response=requests.get(url,headers=headers) soup=BeautifulSoup(response.content,'lxml') for item in soup.select('.ProductCard-container'): try: print('----------------------------------------') #print(item) print(item.select('.ProductCard-name')[0].get_text().strip()) print(item.select('.ProductCard-price--listPrice')[0].get_text().strip()) print(item.select('.ProductCard-price')[0].get_text().strip()) print(item.select('.pl-ReviewStars-reviews')[0].get_text().strip()) print(item.select('.pl-VisuallyHidden')[2].get_text().strip()) print(item.select('.pl-FluidImage-image')[0]['src']) except Exception as e: #raise e print('')
If you route it, it will publish all the information.
Yeah!! We got everything.
If you need to utilize this in creation and need to scale millions of links, after that you need to find out that you will need IP blocked effortlessly by Wayfair. In such case, utilizing a revolving service proxy to replace IPs is required. You can utilize advantages like API Proxies to mount your calls via pool of thousands of inhabited proxies.
If you need to measure the scraping speed and don’t need to fix up infrastructure, you will be able to utilize our Cloud-base scraper RetailGators.com to effortlessly crawl millions of URLs quickly from our system.
If you are looking for the best Scraping Wayfair Products with Python and Beautiful Soup, then you can contact RetailGators for all your queries.
source code: https://www.retailgators.com/scraping-wayfair-products-with-python-and-beautiful-soup.php
0 notes
Link
0 notes